拓扑模式
本文档描述了一些 NSQ 模式,这些模式可以解决各种常见问题。
免责声明:虽然有一些显而易见的技术建议,但本文档通常忽略选择合适工具的深度个人细节、在生产机器上安装软件、管理服务运行的位置、服务配置以及管理运行进程(daemontools、supervisord、init.d 等)。
指标收集
无论您构建的是哪种类型的 Web 服务,在大多数情况下,您都会希望收集某种形式的指标,以了解您的基础设施、用户或业务。
对于 Web 服务,这些指标通常由通过 HTTP 请求发生的事件产生,例如 API。朴素的方法是将此结构化为同步的,直接在 API 请求处理程序中写入您的指标系统。
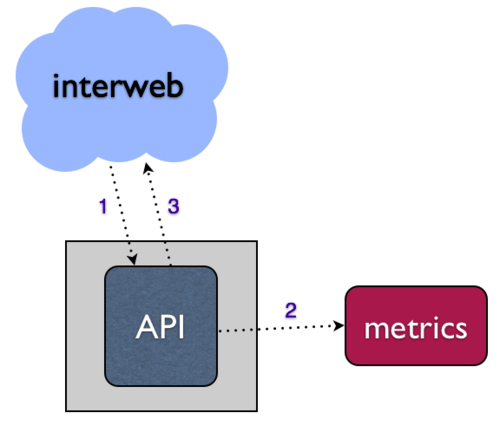
- 当您的指标系统宕机时会发生什么?
- 您的 API 请求会挂起和/或失败吗?
- 您将如何处理 API 请求量增加或指标收集范围扩展的扩展挑战?
解决所有这些问题的一种方法是某种方式异步执行写入指标系统的任务——即,将数据放入某种本地队列中,并通过另一个进程(消费该队列)写入您的下游系统。这种关注点分离使系统更加健壮和容错。在 bitly,我们使用 NSQ 来实现这一点。
简要题外话:NSQ 有主题和通道的概念。基本上,将主题视为消息的唯一流(就像上面的 API 事件流)。将通道视为为给定消费者集的消息流的副本。主题和通道也是独立的队列。这些属性使 NSQ 支持多播(主题将每条消息复制到 N 个通道)和分布式(通道将消息平均分配到 N 个消费者)消息传递。
有关这些概念的更彻底处理,请阅读设计文档和我们在 Golang NYC 演讲的幻灯片,特别是第 19 至 33 页幻灯片详细描述了主题和通道。
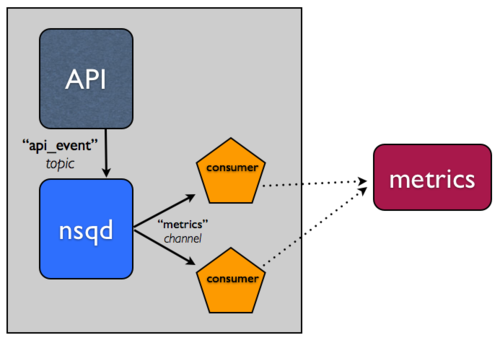
集成 NSQ 很简单,让我们看一个简单的情况:
- 在运行 API 应用程序的主机上运行
nsqd的一个实例。 - 更新您的 API 应用程序以写入本地
nsqd实例来排队事件,而不是直接写入指标系统。为了能够轻松内省和操作流,我们通常以行定向 JSON 格式化这种类型的数据。写入nsqd可以像执行 HTTP POST 请求到/put端点一样简单。 - 使用我们的客户端库之一在您首选的语言中创建一个消费者。这个“工作者”将订阅数据流并处理事件,写入您的指标系统。它也可以在运行 API 应用程序和
nsqd的同一主机上本地运行。
以下是一个使用我们的官方Python 客户端库编写的示例工作者:
除了解耦之外,通过使用我们的官方客户端库,当消息处理失败时,消费者将优雅降级。我们的库有两个关键特性来帮助实现这一点:
- 重试 - 当您的消息处理程序指示失败时,该信息以
REQ(重新排队)命令的形式发送到nsqd。此外,如果消息在可配置的时间窗口内未得到响应,nsqd将自动超时(并重新排队)。这两个属性对于提供交付保证至关重要。 - 指数退避 - 当消息处理失败时,读取器库将延迟接收额外消息的持续时间,该持续时间基于连续失败次数呈指数增长。当读取器处于退避状态并开始成功处理时,会发生相反的序列,直到 0。
这些两个特性共同使系统能够优雅地响应下游失败,自动地。
持久化
好的,太好了,现在您有能力承受指标系统不可用的情况,而不会丢失数据,也不会降低对其他端点的 API 服务。您还有能力通过添加更多工作者实例从同一通道消费来水平扩展此流的处理。
但是,提前考虑给定 API 事件可能想要收集的所有类型指标有点难。
如果有一个此数据流的存档日志供任何未来的操作利用,那不是很好吗?日志通常相对容易冗余备份,使其成为灾难性下游数据丢失情况下的“计划 Z”。但是,您是否希望同一个消费者还承担归档消息数据的责任?可能不会,因为那个“关注点分离”的事情。
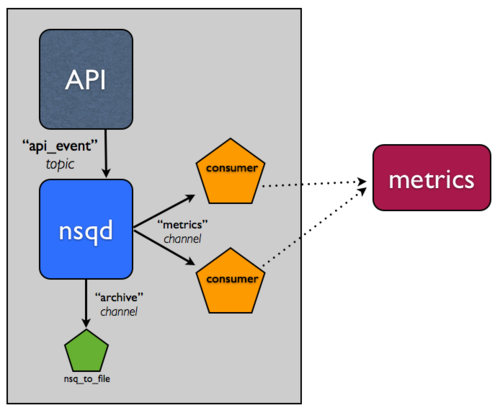
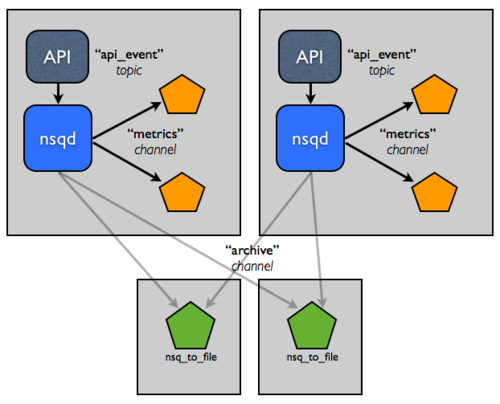
归档 NSQ 主题是一个如此常见的模式,以至于我们构建了一个实用工具,nsq_to_file,它与 NSQ 一起打包,做了您需要的一切。
记住,在 NSQ 中,主题的每个通道都是独立的,并接收所有消息的副本。当归档流时,您可以利用这一点,通过在新通道 archive 上进行归档。实际上,这意味着如果您的指标系统有问题并且 metrics 通道积压,不会影响您用于将消息持久化到磁盘的单独 archive 通道。
因此,在同一主机上添加 nsq_to_file 的一个实例,并使用以下命令行:
/usr/local/bin/nsq_to_file --nsqd-tcp-address=127.0.0.1:4150 --topic=api_requests --channel=archive
分布式系统
您会注意到系统尚未发展到超出单个生产主机,这是一个明显的单点故障。
不幸的是,构建分布式系统很困难。 幸运的是,NSQ 可以帮助。以下更改演示了 NSQ 如何缓解构建分布式系统的一些痛点,以及其设计如何帮助实现高可用性和容错。
假设这个事件流真的很重要。您想要能够容忍主机故障并继续确保消息至少被归档,因此您添加了另一个主机。
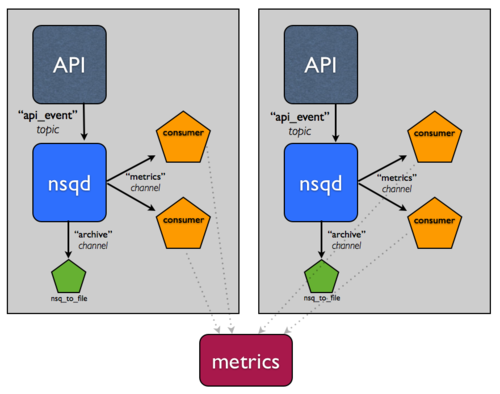
假设您在这些主机前面有一些负载均衡器,现在您可以容忍任何单个主机故障。
现在,让我们说持久化、压缩和传输这些日志的过程正在影响性能。如何将该责任拆分到具有更高 IO 容量的主机层?
这种拓扑和配置可以轻松扩展到两位数的主机,但您仍然手动管理这些服务的配置,这无法扩展。具体来说,在每个消费者中,这个设置硬编码了 nsqd 实例的位置,这很痛苦。您真正想要的是配置演变为基于 NSQ 集群状态在运行时访问。这正是我们构建 nsqlookupd 来解决的。
nsqlookupd 是一个守护进程,它在运行时记录和传播 NSQ 集群的状态。nsqd 实例维护与 nsqlookupd 的持久 TCP 连接,并通过网络推送状态更改。具体来说,一个 nsqd 将自身注册为给定主题的生产者以及它知道的所有通道。这允许消费者查询 nsqlookupd 来确定感兴趣主题的生产者是谁,而不是硬编码该配置。随着时间推移,它们将学习新生产者的存在,并能够绕过故障进行路由。
您需要做的唯一更改是将现有的 nsqd 和消费者实例指向 nsqlookupd(每个人都明确知道 nsqlookupd 实例的位置,但消费者不知道生产者的位置,反之亦然)。拓扑现在看起来像这样:
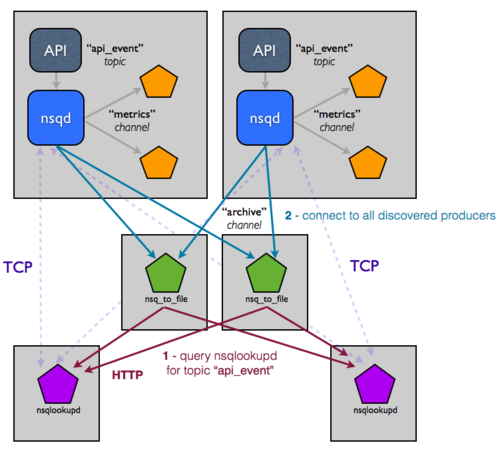
乍一看,这可能看起来更复杂。不过,这是欺骗性的,因为这对不断增长的基础设施的影响很难在视觉上传达。您有效地将生产者与消费者解耦,因为 nsqlookupd 现在充当中间的目录服务。添加依赖给定流的额外下游服务是微不足道的,只需指定您感兴趣的主题(生产者将通过查询 nsqlookupd 被发现)。
但是查找数据的可用性和一致性呢?我们通常建议根据您的期望可用性要求来决定运行多少个。nsqlookupd 不消耗资源,并且可以轻松与其他服务共存。此外,nsqlookupd 实例不需要协调或彼此保持一致。消费者通常只需要一个 nsqlookupd 可用并提供他们需要的信息(他们将联合所有已知 nsqlookupd 实例的响应)。操作上,这使得迁移到新的 nsqlookupd 集变得容易。